Designing a scalable content crawler with a dashboard
Goals:
- To create a comprehensive repository of blogposts from multiple sources.
- Shorten time required to find relevant items to post read and search.
- To provide our users a steady stream of content relevant to the Interests & Topics selected by them.
- Gain insights from the extracted content to create our own machine learning models for classifying items.
Phases
Phase 1
- Setting up a scalable crawling infrastructure in the backend for extracting content from platforms with ready to use APIs eg. Youtube, SoundCloud, Eventbrite, Udemy, Coursera, RSS Feeds.
- Storing the extracted content and relevant meta-data in our database.
- Creation of a Dashboard for the internal team to view extracted items and allow editing or adding tags.
Phase 2
- Enhancement to the Dashboard for adding new sources from the front-end.
- Tweaking the backend to support upload of custom crawler and parsers from the front-end for those new sources.
- Adding functions for refreshing the database to fetch new contents from the sources.
Phase 3
- Setting up Machine Learning infrastructure to train the data with our tagged datasets according to our Topics and Interests.
- Identify new classification models to enrich our existing database.
- Have our own algorithm for rating content with a Z-Score to allow our internal team to find the most relevant content to post on Ceekr.
Data Sources
Most sources can be classified into following:
- API Based: Time required per source: 2 hours
- RSS Feeds: 1 hour per source and 15 mins every week for new content.
- Websites which do not have APIs or RSS Feeds: 1-4 Days depending on the site structure.
The sources can be further classified into following:
- Youtube Channels
- RSS Feeds: Links which provides syndicated feed of all posts from a particular website
- Web Link- Top Level URLs which needs to be crawled by us by writing a scraper to fetch all articles or video links.
- Updates: Some of the URLs has static content which isn’t updated frequently and one time scrape would suffice but some URLs might contain updated content and therefore, the sources need to be classified as such in the dashboard
Functional Requirements
- Authentication and Access Control
- Sign-in/Sign out for an admin account
- Sign-in/Sign out for a user account
- Add/remove new users account with the following access control
- Access restricted to Content Dashboard and Editing & Publishing of Posts
- Access to add new sources
- Access to viewlogs
- Adding Sources
- Since sources can be of either generic type such as Youtube Channels/RSS Feeds or they might require a custom parsers, therefore we would need to specify the category while adding new sources.
- Category of Sources
- RSS Feeds
- Videos: Youtube/Vimeo
- Books: Goodreads
- Events: EventBrite/EventsHigh
- Courses: Coursera, eDX, Udemy
- Quotes: BrainyQuote
- Features of “Adding Sources” Screen
- Adding a new source
- URL
- Category
- Interest & Topic Selection (if already known)
- Option to upload parser
- Viewing
- List of all sources
- Search Bar
- Sorting according to Interests & Topics
- Deleting
- Ability to remove sources
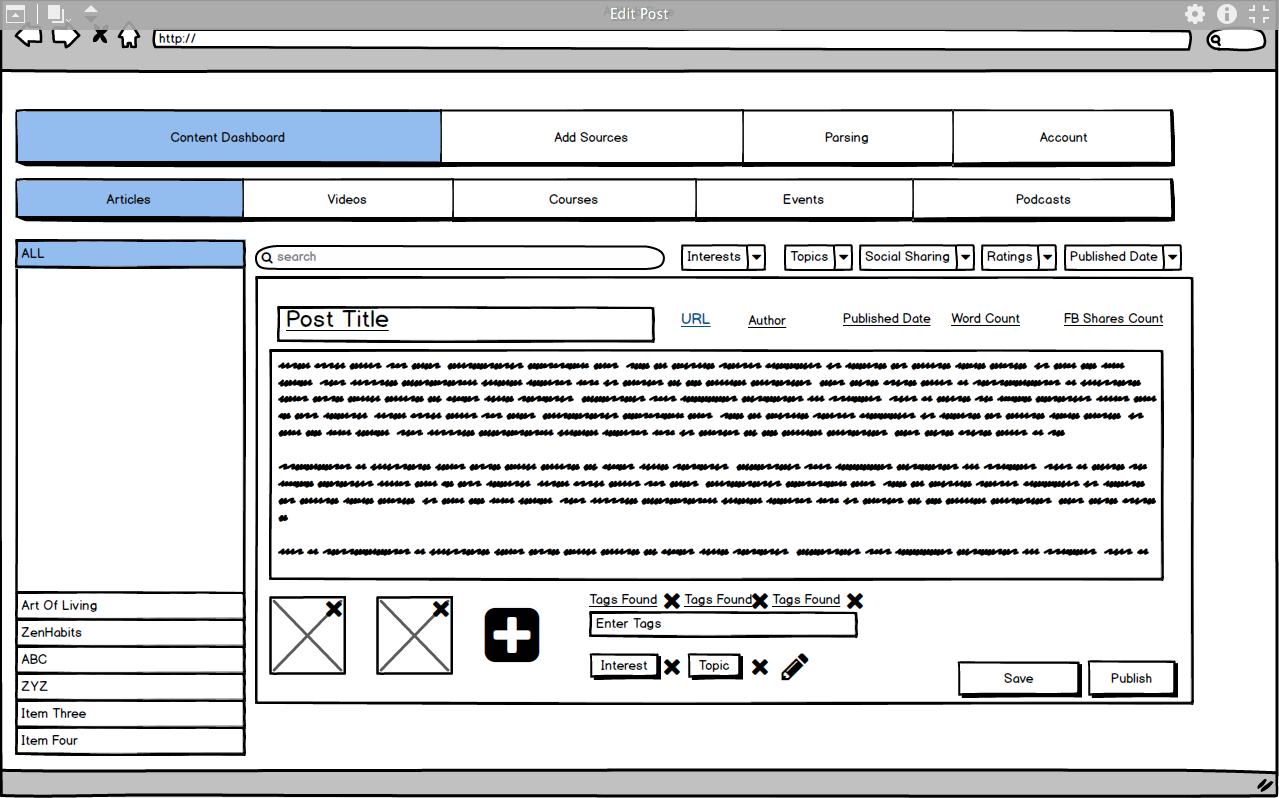
- Content Dashboard
- The content dashboard as the name suggest is the main interface for end-users to view the scraped content in a tabular format with their associated tags and topics. Also, the dashboard has to provide the features of “Adding Interests & Topics” and other search and sorting filters for users.
Features of the content dashboard:
- List of all sources
- List of content items from a particular source.
- Expandable View of the item which displays the complete details of a particular item.
- Ability to add or edit “Interests and Topics” to each and every items
- Search Bar
- Sort by
- Interests
- Topics
- Sort By Social Sharing Nos.
- Sort By Ratings
- Sort By No. of plays in case of Videos
UI Flow
1. Adding Interests & Topics
- 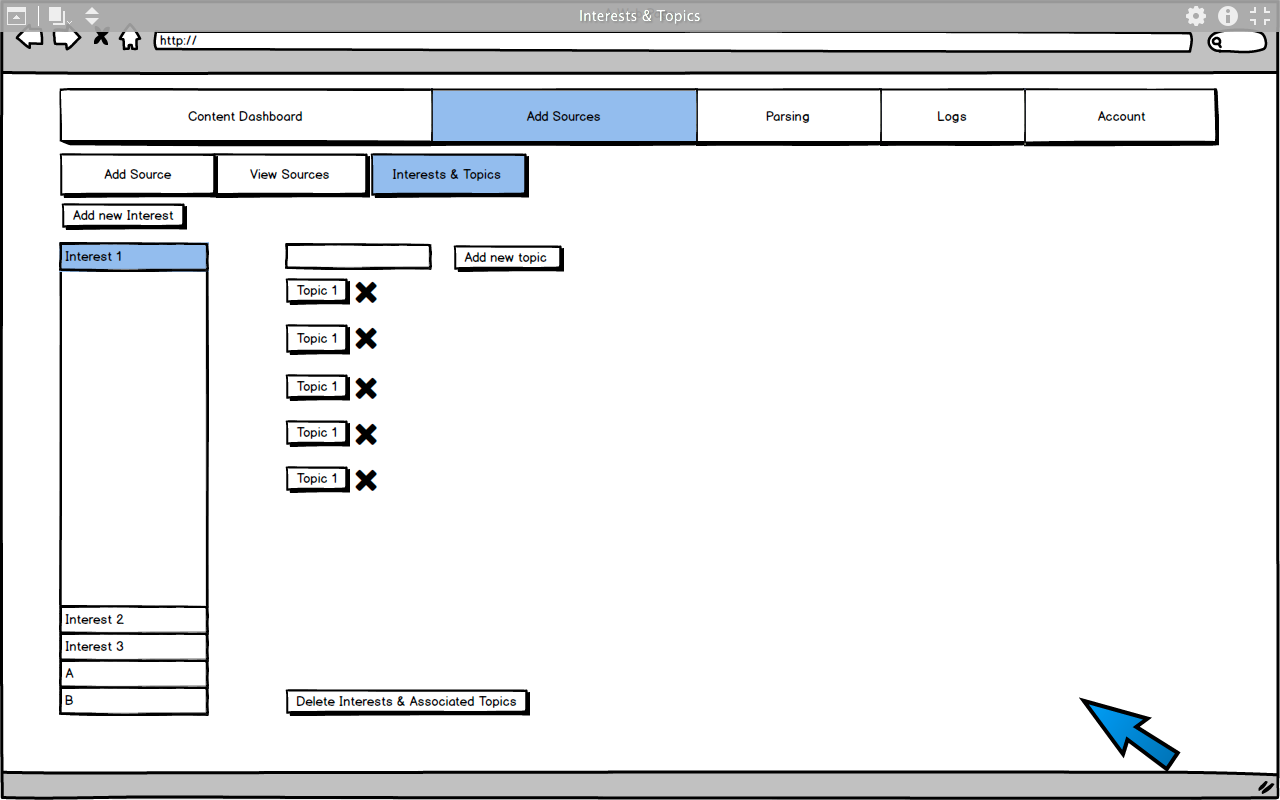 2. Adding a new Data Source
-
2. Adding a new Data Source
-  4. Expanded View of a results obtained from newly added data source
-
4. Expanded View of a results obtained from newly added data source
- 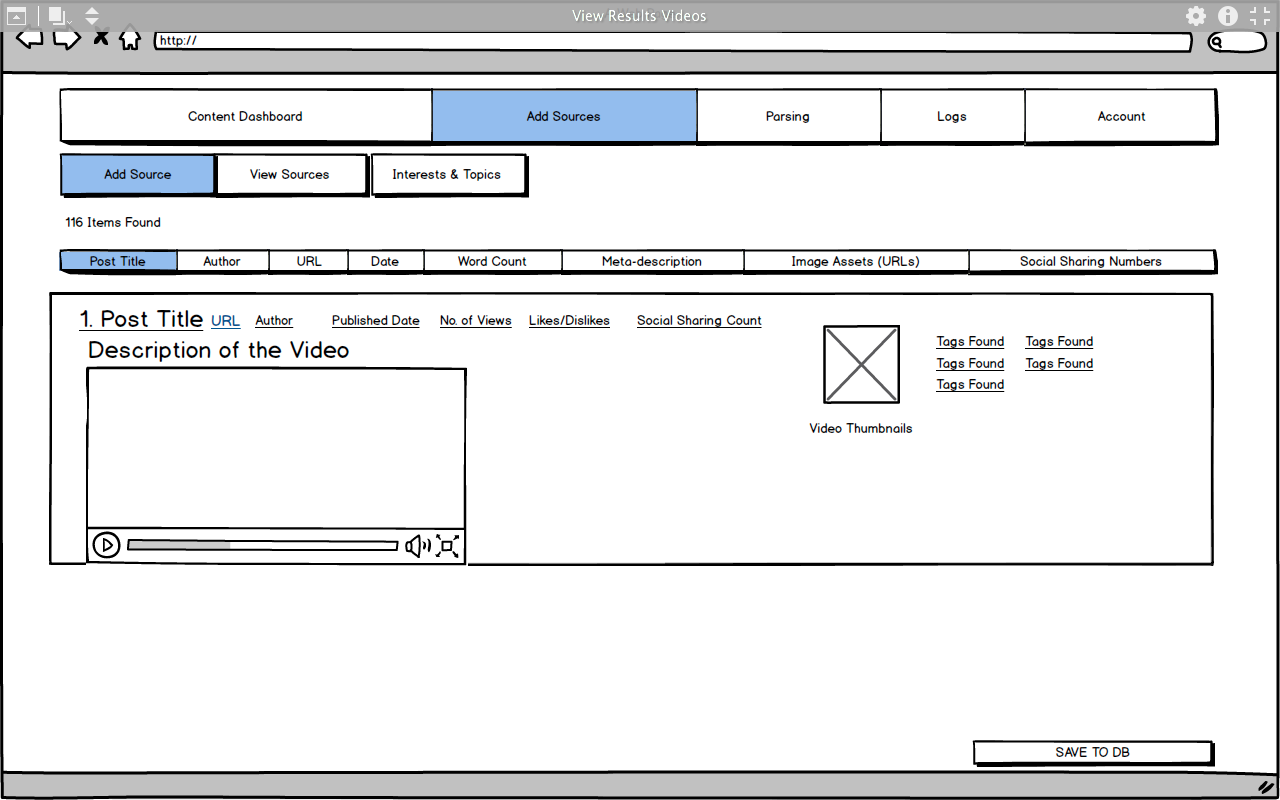 5. View all saved Data Sources
-
5. View all saved Data Sources
- 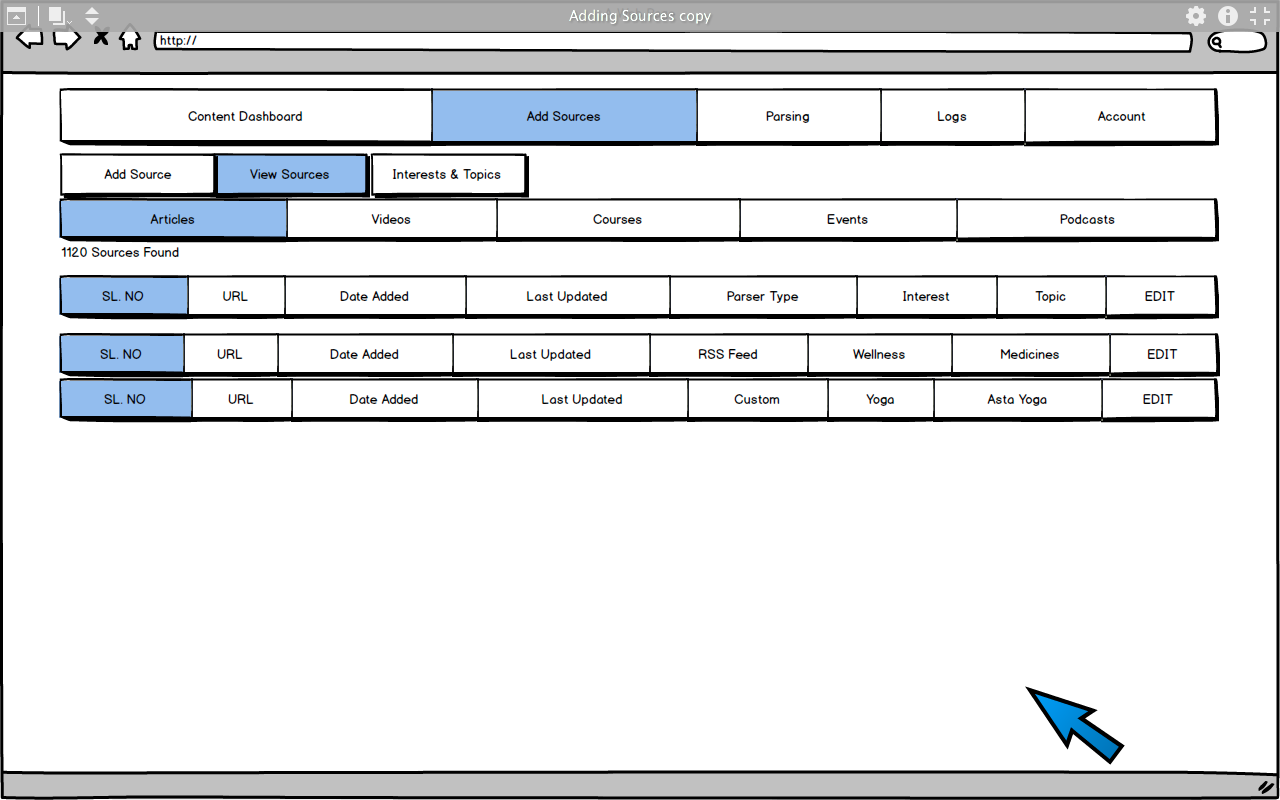 6. View list of items from a source
-
6. View list of items from a source
- 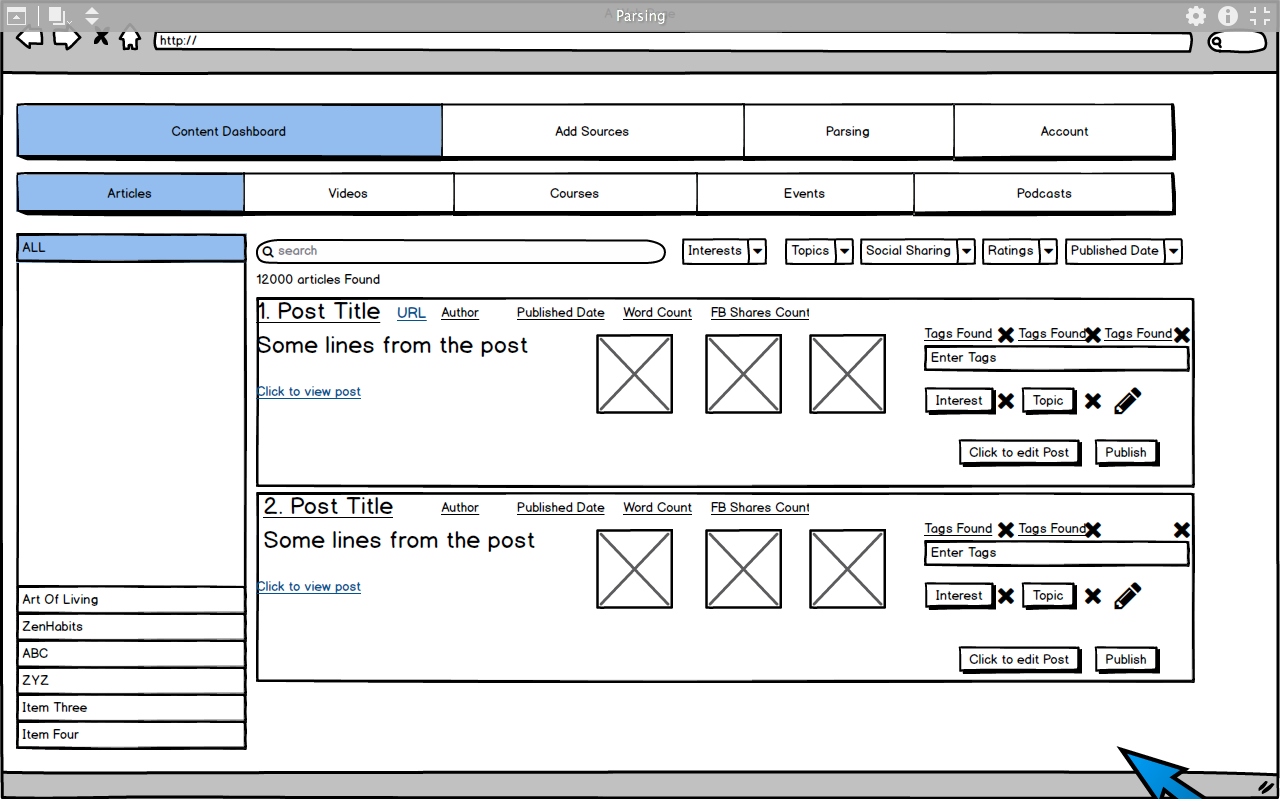 7. Edit Item
-
7. Edit Item
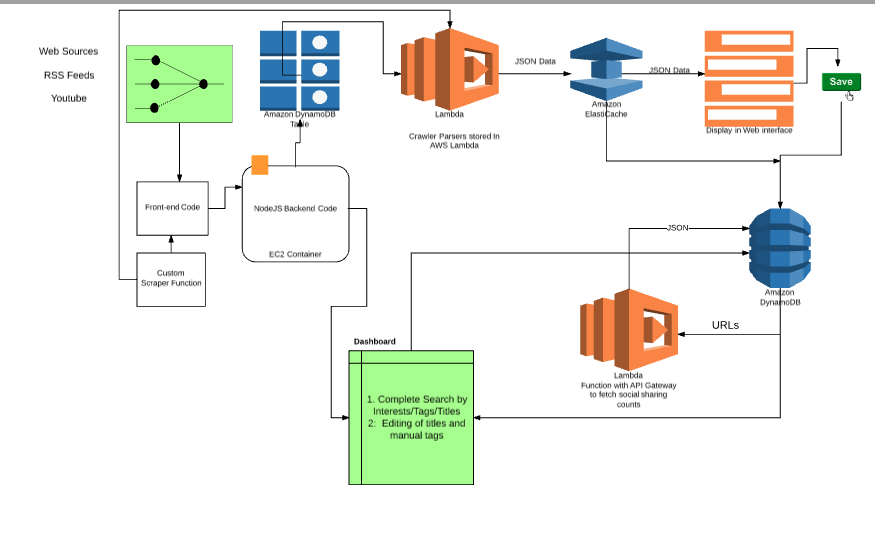
-  ## Technical Architecture
## Technical Architecture
2. Adding a new Data Source
-
4. Expanded View of a results obtained from newly added data source
-
5. View all saved Data Sources
-
6. View list of items from a source
-
7. Edit Item
-
## Technical Architecture
Parsers Types
- Sources supporting APIs
Since most of the content-sources in our repository has pre-defined APIs for accessing content. We can write functions for API access on AWS Lambda and trigger them once an entry of a matching source is placed in DynamoDB.
1. Medium Articles
- One time custom scraper to scrape all articles from Medium publications
2. SoundCloud API
- One time custom scraper to scrape podcasts from SoundCloud
3. Coursera API
4. Udemy API
5. EventBrite API
6. EventsHigh API
7. Youtube also provides an API to retrieve Videos and their meta-data from a particular Channel or Youtube URL
* 
- Custom Parsers
- Using the front-end, a user should be able to upload the functions to be stored in AWS Lambda with a uniqueID for a custom-scraper
- Top levels URLs are parsed through a custom crawler script to generate a list of links which are temporarily stored in DynamoDB
- Once the top-level URLs are crawled, another Lambda Function will be triggered to process each links and store their JSON in an ElasticCache Node
- The front-end would then display the parsed content in the dashboard and if its accepted by the user, the json would then be stored in the DynamoDB.